
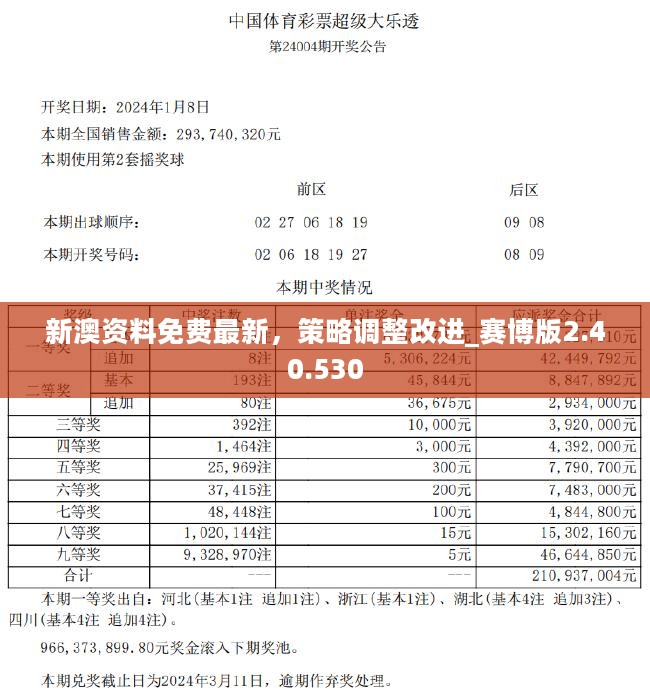
新澳2024年开奖记录分析及数据解读
在当今数字化时代,数据分析已经成为各行各业不可或缺的一部分,无论是金融、医疗、教育还是娱乐行业,通过对数据的深入挖掘和分析,都能发现隐藏在数据背后的趋势和规律,从而为决策提供有力支持,本文将聚焦于“新澳2024年开奖记录”,通过一系列数据分析方法,尝试揭示其中的规律性和趋势性特征,并探讨这些发现对于相关领域的意义和应用价值。
一、引言
随着信息技术的发展以及互联网+模式的普及,越来越多的传统行业开始拥抱数字化转型,彩票业也不例外,在线购彩平台如雨后春笋般涌现,极大地方便了广大彩民朋友参与其中,面对海量的开奖结果数据,如何从中提取有价值的信息成为了一个亟待解决的问题,本文旨在通过对新澳2024年度开奖记录进行系统性地整理与分析,探索其内在规律,以期对未来走势做出更为精准的预测。
二、数据集介绍
本次研究所使用的数据集涵盖了从年初至今(截至2024年5月31日)所有新澳彩票的开奖结果,具体包括但不限于以下几个方面的信息:
日期:每期开奖的具体时间点;
号码组合:当期中奖号码的具体数值;
奖金分配:一等奖至六等奖各奖项对应的金额;
参与人数:购买该期彩票的有效注数总量;
特别事项:如是否有追加投注、复式投注等情况说明。
数据均来源于官方发布渠道或经过授权的第三方平台收集而来,确保了信息的真实性和准确性。
三、方法论框架
为了全面而深入地理解这份庞大的数据集,我们将采用以下几种常见的数据分析手段:
1、描述性统计分析:首先对整个数据集做一个概览性的描述,包括均值、中位数、标准差等基本统计量计算,帮助我们快速了解数据分布情况。
2、时间序列分析:鉴于彩票开奖具有明显的时间属性,因此我们将利用ARIMA模型等经典方法来捕捉长期趋势变化及季节性波动特征。
3、关联规则挖掘:通过Apriori算法寻找频繁出现的号码组合模式,试图找到某些特定条件下更可能出现的结果。
4、聚类分析:基于K-means算法对历史开奖记录进行分组处理,识别出不同类型的开奖模式,并进一步探究它们背后可能的原因。
5、机器学习预测模型构建:结合上述所有分析结果,选取合适的特征变量训练分类器或者回归器,用以预测未来一段时间内的大致走向。
四、实施步骤详解
1. 数据预处理
任何高质量的数据分析工作都离不开良好的数据准备过程,针对本项目而言,我们需要完成以下几个关键步骤:
清洗脏数据:检查原始数据集是否存在缺失值、异常值等问题,并采取相应措施予以修正或删除。
格式转换:统一不同来源的数据格式,便于后续处理,例如将所有日期字段转换为标准格式。
编码处理:对于类别型变量(如奖项级别),需要将其转化为数值形式以便计算机能够正确理解和操作。

特征工程:根据业务需求设计新的指标体系,比如计算连续未中次数、最近N期内出现频率最高的数字等。
2. 描述性统计分析
使用Python中的Pandas库可以轻松实现这一部分内容,以下是一个简单的示例代码片段:
import pandas as pd
加载数据
df = pd.read_csv('new_australia_lottery_2024.csv')
计算基本统计量
summary = df.describe()
print(summary)输出结果会显示每个数值列的最大值、最小值、平均值、四分位数等信息,有助于我们初步掌握整体情况。
3. 时间序列建模
接下来是利用statsmodels库来进行ARIMA模型拟合的过程,首先需要确定合适的参数p, d, q值,这通常可以通过自相关函数图来判断,然后使用fit方法得到最优解。
from statsmodels.tsa.arima.model import ARIMA 假设我们已经找到了合理的阶数 model = ARIMA(df['winning_number'], order=(p,d,q)) result = model.fit() print(result.summary())
此处省略了具体的参数选择过程,实际操作时应依据实际情况灵活调整。
4. 关联规则学习
应用mlxtend库中的apriori函数可以很方便地执行频繁项集挖掘任务,下面展示了一段简单的代码示例:
from mlxtend.frequent_patterns import apriori, association_rules 设定最小支持度阈值 min_support = 0.01 frequent_itemsets = apriori(df, min_support=min_support, use_colnames=True) rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.7) print(rules)
这段程序将返回满足条件的所有强关联规则列表,供进一步分析之用。
5. K-means聚类实验
Scikit-learn提供了非常强大的工具集用于执行各种聚类算法,下面是关于如何使用KMeansClusterer的一个简单演示:
from sklearn.cluster import KMeans
import numpy as np
假设我们已经选择了适合的特征向量X
kmeans = KMeans(n_clusters=3, random_state=42)
kmeans.fit(X)
labels = kmeans.predict(X)
centroids = kmeans.cluster_centers_
print("Cluster Centers:
", centroids)注意这里的X应该是之前提到的经过特征工程后的矩阵形式表示的数据。
6. 机器学习模型训练
最后一步是基于前面所有准备工作的基础上挑选出最有效的特征输入到选定的学习器当中去,这里推荐尝试几种不同的算法看看哪种效果最好,比如逻辑回归、支持向量机、随机森林等,同时不要忘记留出一部分样本作为测试集评估模型性能哦!
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
划分训练测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
初始化分类器
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
predictions = clf.predict(X_test)
print("Accuracy: ", accuracy_score(y_test, predictions))五、结果讨论与展望
经过上述一系列复杂的数据处理流程之后,我们可以获得许多有趣的见解,可能会发现某些特定时间段内某种类型的组合更容易被抽中;或者是当达到一定条件时(如连续多期无人中奖),下一期出现大奖的概率显著增加等等,这些都是值得进一步探究的方向,由于篇幅限制,本文仅能提供一个大致框架性的指导思路,具体细节还需要读者根据自身兴趣点深入研究,希望本文能够为大家打开一扇通往更加丰富多彩的世界的大门!



 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号